Module axi
This document contains technical documentation for the axi module.
To browse the source code, visit the repository on GitHub.
This module contains a large set of AXI components written in VHDL. They are based around record types in axi_pkg.vhd that make it convenient to work with the AXI signals.
See also the Module bfm for tools to efficiently simulate your AXI design.
axi_address_fifo.vhd
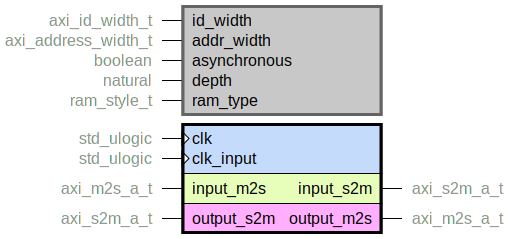
FIFO for AXI address channel (AR or AW). Can be used as clock crossing by setting
the asynchronous generic. By setting the width generics, the bus is packed
optimally so that no unnecessary resources are consumed.
Note
If asynchronous operation is enabled, the constraints of asynchronous_fifo.vhd must be used.
axi_address_range_checker.vhd

Check that an AXI address channel does not produce transactions that are out of range.
Warning
This core checker is not suitable for instantiation in your design. Use axi_read_range_checker.vhd or axi_write_range_checker.vhd instead.
axi_b_fifo.vhd

FIFO for AXI write response channel (B). Can be used as clock crossing by setting
the asynchronous generic. By setting the id_width generic, the bus is packed
optimally so that no unnecessary resources are consumed.
Note
If asynchronous operation is enabled, the constraints of asynchronous_fifo.vhd must be used.
axi_pkg.vhd
Data types for working with AXI4 interfaces
Based on the document “ARM IHI 0022E (ID022613): AMBA AXI and ACE Protocol Specification”, available here: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ihi0022e/index.html
axi_r_fifo.vhd

FIFO for AXI read response channel (R). Can be used as clock crossing by setting
the asynchronous generic. By setting the width generics, the bus is packed
optimally so that no unnecessary resources are consumed.
Note
If asynchronous operation is enabled, the constraints of asynchronous_fifo.vhd must be used.
axi_read_cdc.vhd
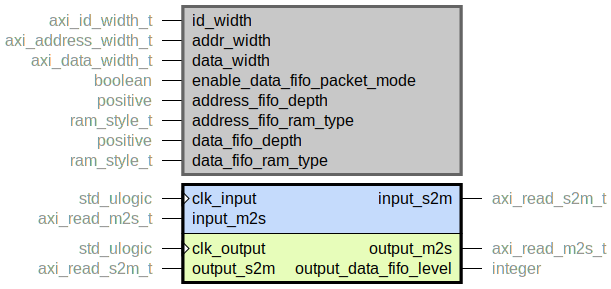
Clock domain crossing of a full AXI read bus using asynchronous FIFOs for the AR and R
channels.
By setting the width generics, the bus is packed
optimally so that no unnecessary resources are consumed.
Note
The constraints of asynchronous_fifo.vhd must be used.
axi_read_pipeline.vhd

Pipeline the AR and R channels of an AXI read bus.
The generics can be used to control throughput settings, which affects the logic footprint.
axi_read_range_checker.vhd

Rudimentary simulation runtime checker that an AXI master does not produce transactions that are out of the range of a downstream memory slave. Suitable to instantiate at the end of your AXI chain, right before the AXI memory slave.
This entity is meant for simulation, but since it contains only quite simple assertions it should be no problem for a synthesis tool to strip it. However, it is probably a good idea to instantiate it within a simulation guard:
axi_range_checker_gen : if in_simulation generate
axi_read_range_checker_inst : entity work.axi_read_range_checker
generic map (
...
);
end generate;
axi_read_throttle.vhd

Performs throttling of an AXI read bus by limiting the number of outstanding transactions, which makes the AXI master well behaved.
This entity is to be used in conjunction with a data FIFO (fifo.vhd
or asynchronous_fifo.vhd) on the input.r side.
Using the level from that FIFO, the throttling will make sure that address
transactions are not made that would result in the FIFO becoming full. This
avoids stalling on the throttled_s2m.r channel.
![digraph my_graph {
graph [dpi = 300];
rankdir="LR";
ar [shape=none label="AR"];
r [shape=none label="R"];
{
rank=same;
ar;
r;
}
r_fifo [label="" shape=none image="fifo.png"];
r -> r_fifo [dir="back"];
axi_read_throttle [shape=box label="AXI read\nthrottle"];
ar:e -> axi_read_throttle;
r_fifo:e -> axi_read_throttle [dir="back"];
r_fifo:s -> axi_read_throttle:s [label="level"];
axi_slave [shape=box label="AXI slave" height=2];
axi_read_throttle -> axi_slave [dir="both" label="AXI\nread"];
}](../../_images/graphviz-c8fdb89591f0ad65ec46b3b0aaec6928d9c53f92.png)
To achieve this it keeps track of the number of outstanding beats that have been negotiated but not yet sent.
Warning
The FIFO implementation must update the level counter on the same rising clock edge as the FIFO
write transaction, i.e. the input.r transaction.
Otherwise the throttling will not work correctly.
This condition is fulfilled by fifo.vhd, asynchronous_fifo.vhd and most other
FIFO implementations.
The imagined use case for this entity is with an AXI crossbar where the throughput should not be limited by one port starving out the others by being ill behaved. In this case it makes sense to use this throttler on each port.
However if a crossbar is not used, and the AXI bus goes directly to an AXI slave that has FIFOs
on the AR and R channels, then there is no point to using this throttler.
These FIFOs can be either in logic (in e.g. an AXI DDR4 controller) or in the “hard”
AXI controller in e.g. a Xilinx Zynq device.
Resource utilization
This entity has netlist builds set up with automatic size checkers in module_axi.py. The following table lists the resource utilization for the entity, depending on generic configuration.
Generics |
Total LUTs |
FFs |
Maximum logic level |
|---|---|---|---|
data_fifo_depth = 1024 max_burst_length_beats = 256 id_width = 6 addr_width = 32 full_ar_throughput = False |
41 |
76 |
8 |
axi_simple_read_crossbar.vhd
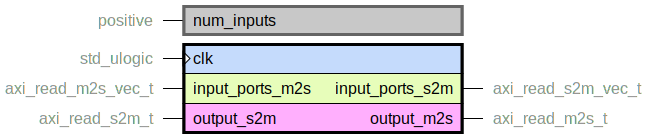
Simple N-to-1 crossbar for connecting multiple AXI read masters to one port.
It is simple in the sense that there is no separation of AXI AR and R channels
with separate queues.
After a port has been selected for address transaction, the crossbar is
locked on that port until it has finished it’s read response transactions.
After that, the crossbar moves on to do a new address transaction on, possibly,
another port.
Due to this it has a very small logic footprint but will never reach full utilization of the data channels. In order to get higher throughput, further address transactions should be queued up to the slave while a read response burst is running.
Arbitration is done in simplest most resource-efficient manner possible, which means that one input port can block others if it continuously sends transactions.
Resource utilization
This entity has netlist builds set up with automatic size checkers in module_axi.py. The following table lists the resource utilization for the entity, depending on generic configuration.
Generics |
Total LUTs |
FFs |
Maximum logic level |
|---|---|---|---|
num_inputs = 4 |
120 |
5 |
4 |
axi_simple_write_crossbar.vhd
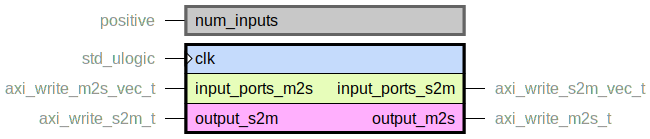
Simple N-to-1 crossbar for connecting multiple AXI write masters to one port.
It is simple in the sense that there is no separation of AXI AW/W/B channels
with separate queues.
After a port has been selected for address transaction, the crossbar is
locked on that port until it has finished it’s write (W) transactions and write
response (B) transaction. After that, the crossbar moves on to do a new address transaction
on, possibly, another port.
Due to this it has a very small logic footprint but will never reach full
utilization of the data channels.
In order to reach higher throughput there needs to be separation of the channels so that further
AW transactions are queued up while other W and B transactions are running,
and further W transactions are performed while waiting for other B transactions.
Arbitration is done in simplest most resource-efficient manner possible, which means that one input port can block others if it continuously sends transactions.
Resource utilization
This entity has netlist builds set up with automatic size checkers in module_axi.py. The following table lists the resource utilization for the entity, depending on generic configuration.
Generics |
Total LUTs |
FFs |
Maximum logic level |
|---|---|---|---|
num_inputs = 4 |
298 |
5 |
4 |
axi_w_fifo.vhd

FIFO for AXI write data channel (W). Can be used as clock crossing by setting
the asynchronous generic. By setting the data_width generic, the bus is packed
optimally so that no unnecessary resources are consumed.
Note
If asynchronous operation is enabled, the constraints of asynchronous_fifo.vhd must be used.
axi_write_cdc.vhd
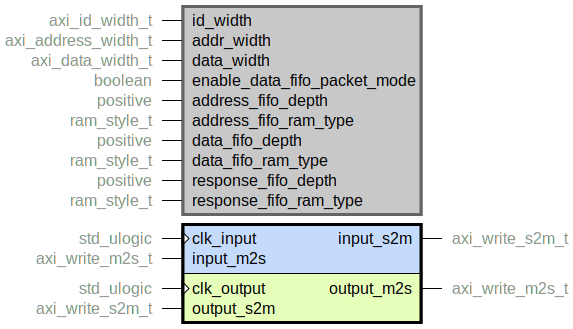
Clock domain crossing of a full AXI write bus using asynchronous FIFOs for the AW, W
and B channels.
By setting the width generics, the bus is packed
optimally so that no unnecessary resources are consumed.
Note
The constraints of asynchronous_fifo.vhd must be used.
axi_write_pipeline.vhd

Pipeline the AW, W and B channels of an AXI write bus.
The generics can be used to control throughput settings, which affects the logic footprint.
axi_write_range_checker.vhd

Rudimentary simulation runtime checker that an AXI master does not produce transactions that are out of the range of a downstream memory slave. Suitable to instantiate at the end of your AXI chain, right before the AXI memory slave.
This entity is meant for simulation, but since it contains only quite simple assertions it should be no problem for a synthesis tool to strip it. However, it is probably a good idea to instantiate it within a simulation guard:
axi_range_checker_gen : if in_simulation generate
axi_write_range_checker_inst : entity work.axi_write_range_checker
generic map (
...
);
end generate;
axi_write_throttle.vhd

Performs throttling of an AXI write bus with the goal of making the AXI write master
well behaved.
This entity makes sure that AWVALID is asserted in the same clock cycle as the first
WVALID of the corresponding data burst.
This, along with the two conditions below, realize the most strict condition imaginable for an
AXI write master interface being well behaved.
It guarantees that not a single clock cycle is wasted on the throttled interface.
Should be used in conjunction with a data FIFO (fifo.vhd or asynchronous_fifo.vhd) on the
input.wside that has packet mode enabled. This ensures that onceWVALIDhas been asserted, it remains high until theWLASTtransaction has occurred.The
input.b.readysignal should be statically'1'. This ensures thatBmaster on thethrottledside is never stalled.
![digraph my_graph {
graph [dpi=300];
rankdir="LR";
aw [shape=none label="AW"];
w [shape=none label="W"];
b [shape=none label="B"];
{
rank=same;
aw;
w;
b;
}
w_fifo [label="" shape=none image="fifo.png"];
w -> w_fifo;
axi_write_throttle [shape=box label="AXI write\nthrottle"];
aw:e -> axi_write_throttle;
w_fifo:e -> axi_write_throttle;
b -> axi_write_throttle [dir="back"];
axi_slave [shape=box label="AXI slave" height=2];
axi_write_throttle -> axi_slave [dir="both" label="AXI\nwrite"];
}](../../_images/graphviz-c1f3d0143bbf35aa1292f5bd6c378d1e71093672.png)
The imagined use case for this entity is with an AXI crossbar where the throughput should not be limited by one port starving out the others by being ill-behaved. In this case it makes sense to use this throttler on each port.
However if a crossbar is not used, and the AXI bus goes directly to an AXI slave that has FIFOs
on the AW and W channels, then there is no point to using this throttler.
These FIFOs can be either in logic (in e.g. an AXI DDR4 controller) or in the “hard”
AXI controller in e.g. a Xilinx Zynq device.
Resource utilization
This entity has netlist builds set up with automatic size checkers in module_axi.py. The following table lists the resource utilization for the entity, depending on generic configuration.
Generics |
Total LUTs |
FFs |
Maximum logic level |
|---|---|---|---|
5 |
2 |
2 |